Machine learning is a form of artificial intelligence designed to make devices smarter. Innovative software functionality often implements software artifacts created using machine learning. Machine learning enables the rapid identification of patterns, which is an important asset in automotive electronics.
Applications, functional software, sensors and actuators benefit from machine learning models’ ability to recognize patterns faster than humans can. We need these capabilities for advanced driver-assistance systems and autonomous driving as well as in other systems, such as predicting wear and tear.
The Machine Learning Engineering process group within the Automotive SPICE® process assessment model (PAM) v4.0, along with standards such as ISO/IEC 23053:2022, establishes how machine learning-based applications can be used in the development of automotive electronics in compliance with standard requirements for safety and reliability. This standard complements and deepens the application of Automotive SPICE® and provides an approach to support quality development and a reliable basis for functional safety, safety of the intended function (SOTIF) and cybersecurity.
Machine learning foundations
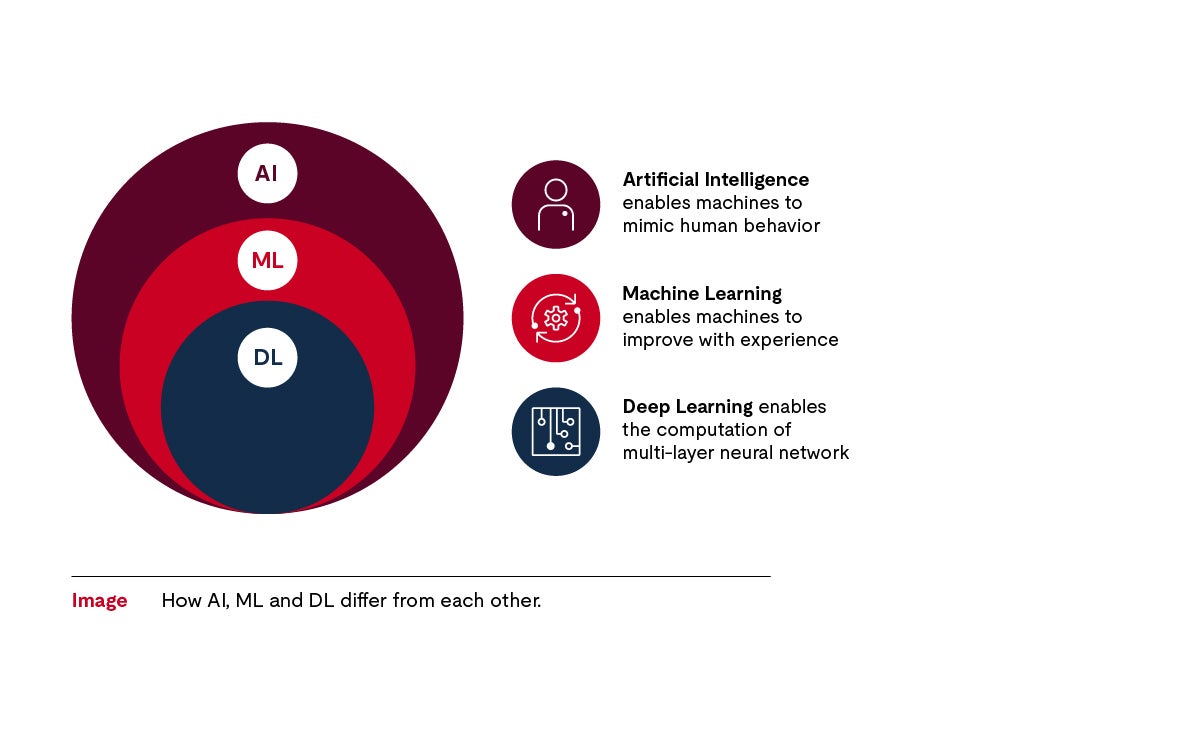
Artificial intelligence is explained and categorized in many different ways in the literature. As it relates to existing applications, artificial intelligence is an umbrella term that encompasses deep learning and machine learning and is seen in applications such as chatbots.
Chatbots use a pre-trained language model — a large neural network that has been trained on massive amounts of text data, typically using unsupervised learning techniques. Based on this data corpus, a chatbot can generate answers to questions posed by a human using static probabilities.
Machine learning is a subset of artificial intelligence that also uses algorithms created on the basis of the data provided. These algorithms are used to make a machine — such as application software or components — more powerful. For example, in automotive electronics, machine learning provides the ability to recognize and interpret traffic signs.
Deep learning is a subset of machine learning that uses more complex algorithms and neural networks that simulate the structure of neurons of the brain.
Solving pattern-based problems with machine learning
Machine learning solves problems where patterns can be used. The developers or the organization must collect a large amount of sample data — such as traffic signs. The algorithm transforms the unstructured information from a dataset into a standardized format.
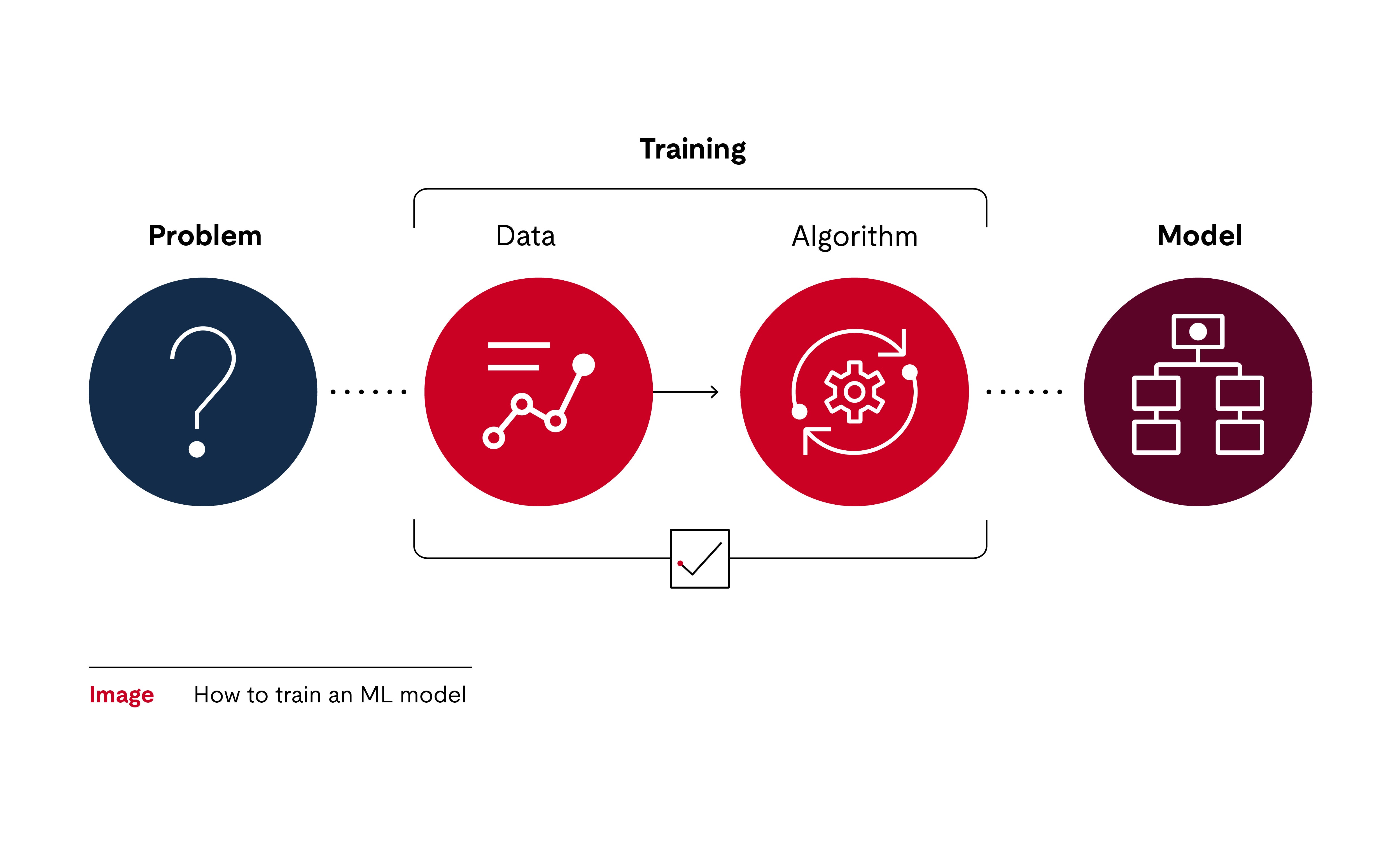
What is important to understand from a machine learning engineering perspective is, that no human programmed this software artifact. The algorithm optimizes and refines itself through the training process. Through this process, it tries to approximate behavior and learn meaningful patterns from examples. There is not just one algorithm but countless ways to reach the goal. The machine learning engineer selects the most suitable algorithm for further use.
The algorithm distills instructions independently from the dataset. This is called machine learning because the algorithm teaches itself how to structure the given data into information. For the training to produce the desired result, the algorithm is told how to interpret the environment from an engineering point of view. In our traffic sign recognition example, it may detect patterns by analyzing the color distribution and assigning the most probable traffic sign names.
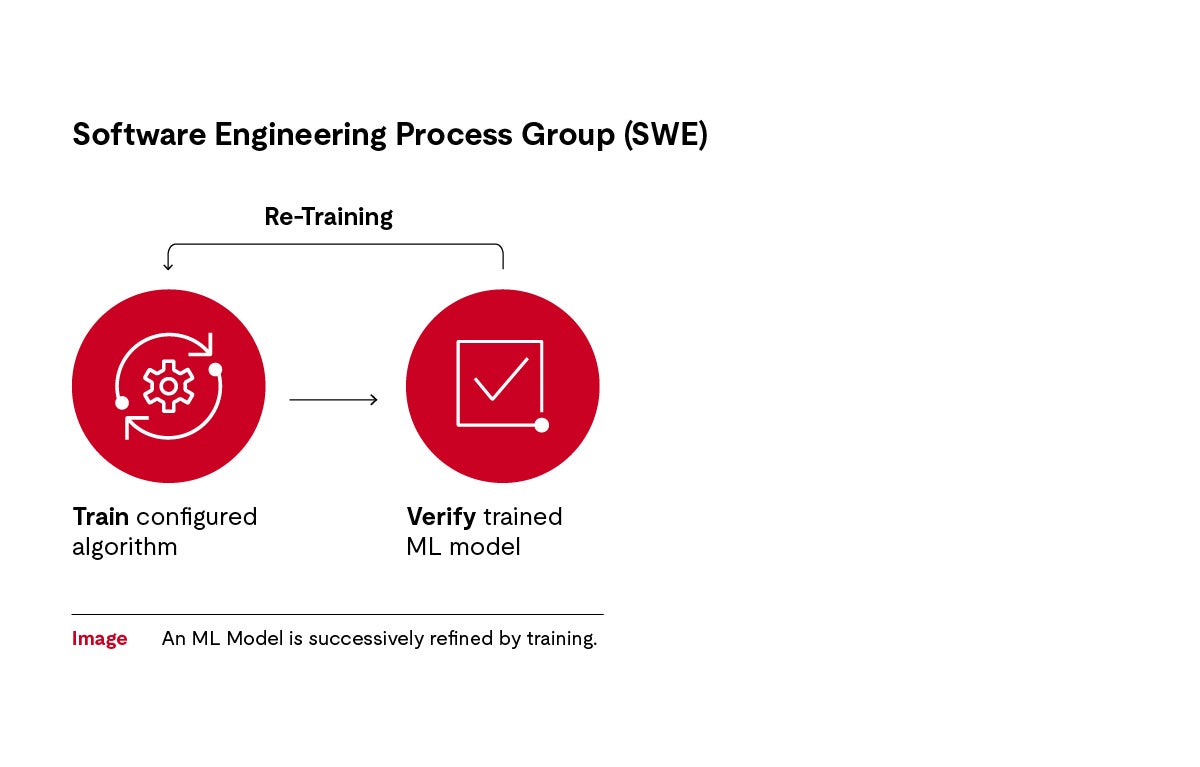
This training is an iterative process — a research and development (R&D) approach with trial-and-error cycles. Machine learning engineers regularly check whether the algorithm can structure the training data to assign it to the names of the traffic signs. The machine learning engineer then refines the algorithm with additional training material and repeats the process until a robust model results. The engineer exposes the algorithm to the data and checks the outputs.
The model is the asset that contains all the information. This model can then be implemented in the application software. In our example, the model contains a decision tree that tells us how the image colors are linked to different traffic signs.
The model is verified against an independent dataset to ensure that the model is not trained against the data but against the possible situations in the actual environment.
Because the software was not written by a human being, it creates a black box. The algorithm delivers a result — the model. However, the structure of this model cannot be understood with reasonable effort, so we face the challenge of writing reliable software for a safety-critical system without knowing how it works. This is unacceptable from a quality assurance perspective.
Due to the development approach of machine learning, we face new challenges in quality, functional safety and cybersecurity with the introduction of machine learning models in automotive software and in the backend.
Conventional processes provided by standards such as Automotive SPICE® do not work in conjunction with machine learning. In conventional development, you describe the requirements — what you want the software to do. Then you design the architecture — the organization of your software to provide those functions. Finally, for each unit, you define the details that need to be implemented in the code. Along these levels of detail, you run a series of tests.
In machine learning, there are no such formalized tests. Once the developer is satisfied with the result that meets the predefined criteria, the algorithm is tested and released. Verification and testing of machine learning is therefore mostly based on data labeling, training, anti-biasing and ensuring that key performance indicators (KPIs) are met.
From a quality assurance perspectivcomis aspect by imagining the training, verification and testing process as the layers of an onion to illustrate the determined sequence and the dependencies.
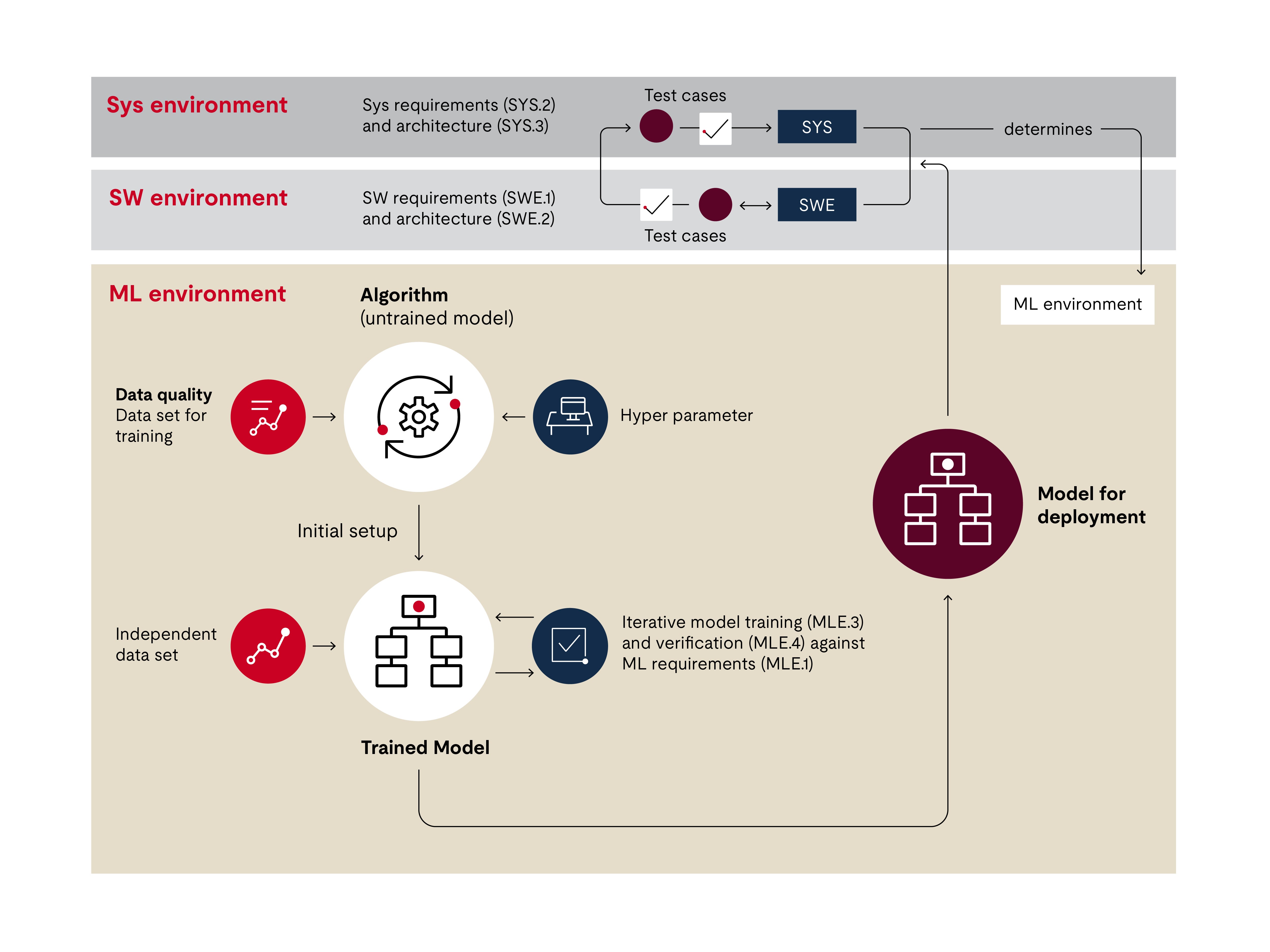
At the inner layer of the onion is the algorithm. This has been configured for the desired functionality by the machine learning engineer. This customization can, for example, control the number of neural connections, or nodes. If an update to the algorithm is required, new training and verification is needed. Together, the two layers form the trained model. The testing of the model then acts on these two layers.
Because the model is based on training data, data quality is a key issue. In the diagram of the onion, we see that there is a separate process addressing the data.
Applying the machine learning engineering model for Automotive SPICE®
Processes for software artifacts created by machine learning are software engineering processes. Therefore, the Automotive SPICE® standard is based on the software engineering processes. The requirements for the software to be created are formulated in the requirements process (SWE.1); this is is the case for any automotive electronics software. For this purpose, the relevant system requirements are transformed into a set of software requirements, some of which then concern software artifacts that are to be created using machine learning. The software architecture, as an outcome of the SW Architectural Design (SWE.2), regulates what these are.
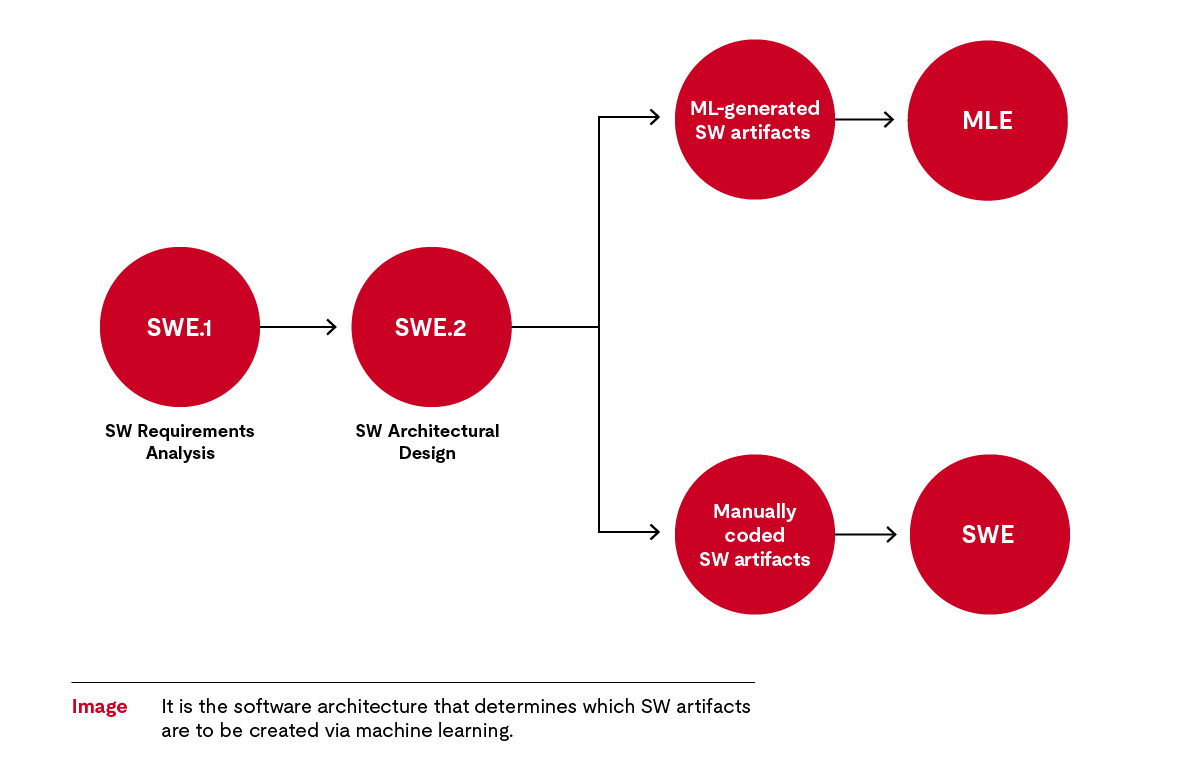
In machine learning, the software artifacts are to be generated by an algorithm, so we need special processes that replace the classical software detailed design.
In the diagram below, the top left of the V is the machine learning requirements analysis process (MLE.1). The task of this process is to determine special requirements for machine learning from the software requirements.
This is followed by the architecture for machine learning (MLE.2). This process concerns the machine learning architecture supporting the training and creation of the algorithm as well as other necessary software, such as pre- and post-processing software.
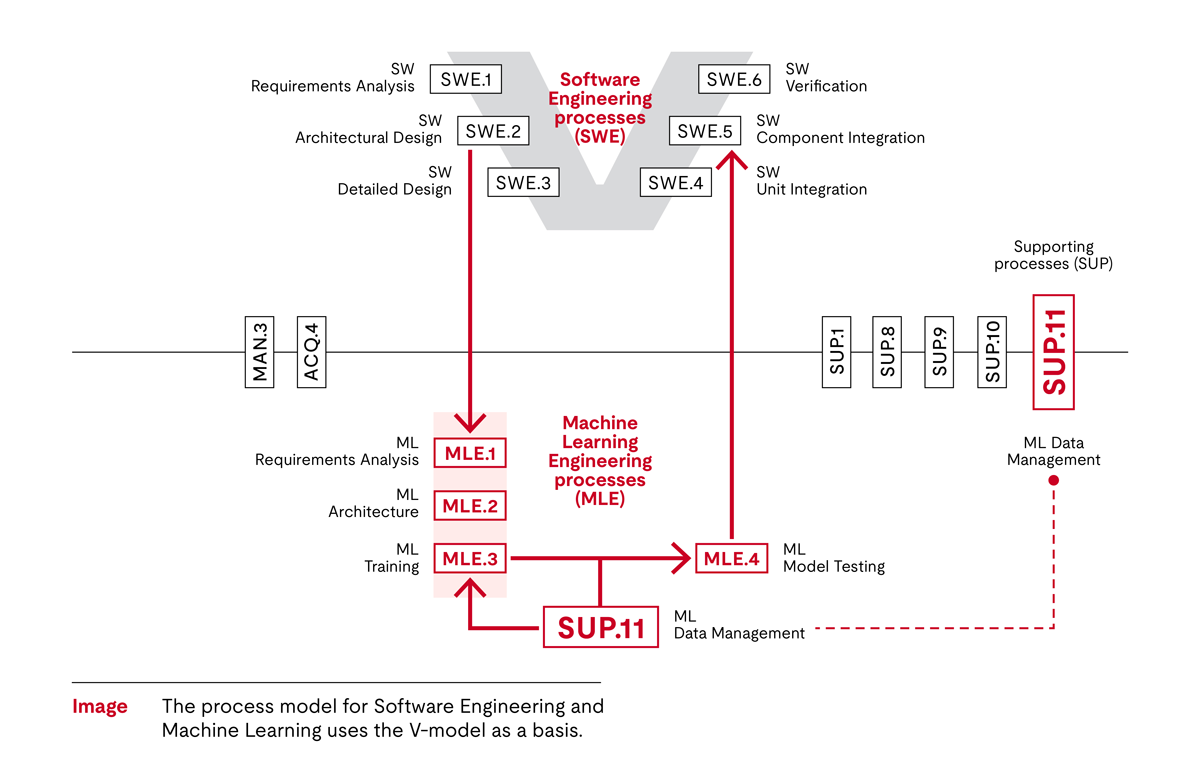
On the right side of the V is the training of the algorithm. It is crucial that the model not only performs but also, above all, that it meets the specified requirements (MLE.3). As mentioned above, the training is a systematic, trial-and-error approach.
During testing, it must be ensured that both the trained machine learning model and the implemented machine learning model meet the specifications of the machine learning requirements (MLE.4). We distinguish between the trained model, which has been verified, and the deployed model, which can be used in the actual software of the system.
Then, in software integration testing (SWE.5), all artifacts are integrated and tested together. This is where all artifacts come together, regardless of whether they were coded in a conventional way or trained using a machine learning approach.
However, this does not cover data quality. The new support process, machine learning data management (SUP.11), is about defining the data relevant for machine learning in accordance with the machine learning data requirements and ensuring the integrity of the data.
Data management is a very complex task that is often addressed by large groups within an organization, so there is a separate data management process assessment model.
In Automotive SPICE® v4.0, machine learning becomes part of the standard. In connection with the conventionally developed software, machine learning development can now be addressed from a quality point of view. This also serves as a good basis for functional safety and cybersecurity.
Why choose UL Solutions Software Intensive Systems for Automotive SPICE® support?
As part of our strategy to systematically improve development processes in the automotive electronics sector, UL Solutions Software Intensive Systems is an official licensee of Automotive SPICE®, a trademark of the Association of the German Automotive Industry (VDA QMC).
We can support automotive original equipment manufacturers (OEMs) and suppliers in:
- Achieving the required capability levels within key development processes.
- Systematically improving existing workflows and methods.
- Evaluating the status of process improvements through formal assessments and gap analysis.
- Fulfilling the requirements of Automotive SPICE® in harmony with security, functional safety and agile methods.
- Training staff and assessors.
X
Get connected with our team
Thanks for your interest in our products and services. Let's collect some information so we can connect you with the right person.
Please wait…
Characters remaining