Maschinelles Lernen ist eine Form der künstlichen Intelligenz, mit der Geräte intelligenter gestaltet werden. Innovative Softwarefunktionen setzen häufig Softwareartefakte ein, die mit Hilfe von maschinellem Lernen erstellt wurden. Maschinelles Lernen ermöglicht die schnelle Erkennung von Mustern, dies ist ein wichtiger Vorteil in der Automobilelektronik.
Anwendungen, Funktionssoftware, Sensoren und Aktoren profitieren von der Fähigkeit der maschinellen Lernmodelle, die Muster schneller zu erkennen als der Mensch. Gerade für fortschrittliche Fahrerassistenzsysteme und autonomes Fahren, aber auch für andere Systeme, wie z. B. die Vorhersage von Verschleißerscheinungen, benötigen wir diese Fähigkeiten.
Die Prozessgruppe Machine Learning Engineering innerhalb des Automotive SPICE® Prozess-Assessmentmodells (PAM) v4.0 legt zusammen mit Normen wie die ISO/IEC 23053:2022 fest, wie auf maschinellem Lernen basierende Anwendungen in der Entwicklung von Automobilelektronik unter Einhaltung der Standardanforderungen für Sicherheit und Zuverlässigkeit eingesetzt werden können. Diese Norm ergänzt und erweitert die Anwendung von Automotive SPICE® und bietet einen Ansatz zur Unterstützung der Qualitätsentwicklung und eine zuverlässige Grundlage für funktionale Sicherheit, Sicherheit der vorgesehenen Funktion (SOTIF) und Cybersicherheit.
Grundlagen des maschinellen Lernens
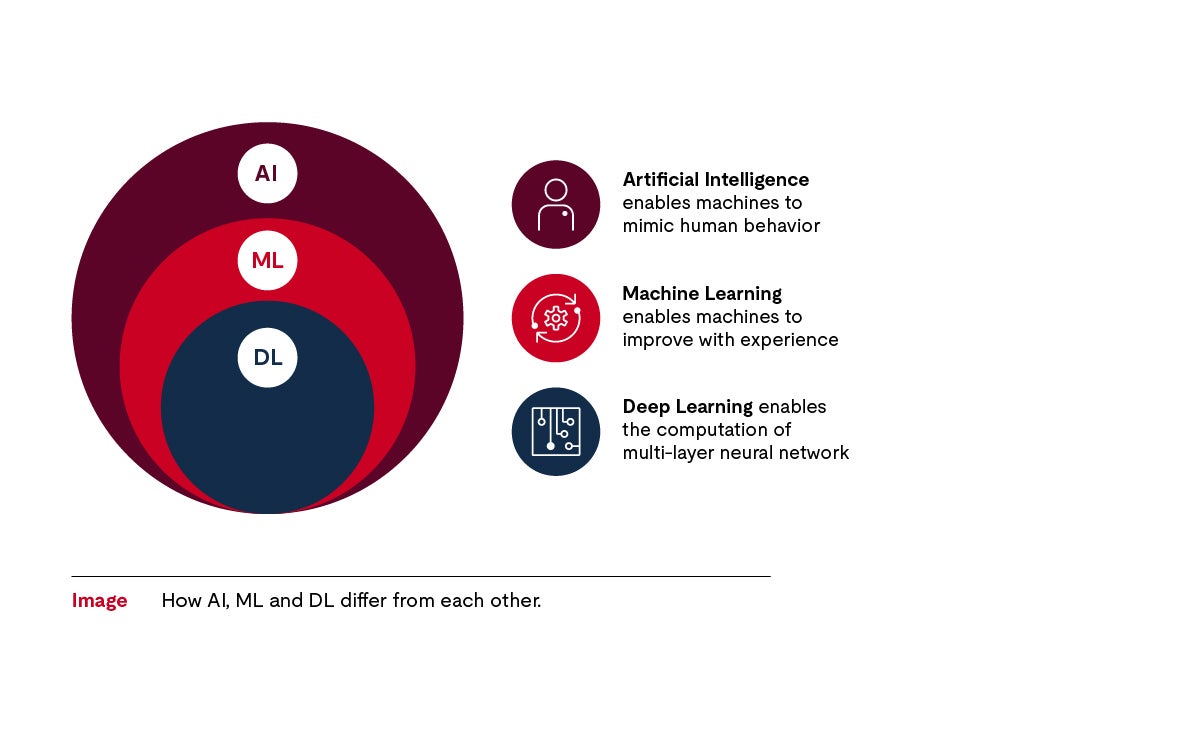
Künstliche Intelligenz wird in der Literatur auf viele verschiedene Arten erklärt und kategorisiert. In Bezug auf existierende Anwendungen ist künstliche Intelligenz ein Oberbegriff, der Deep Learning und maschinelles Lernen umfasst und in Anwendungen wie Chatbots zu finden ist.
Chatbots verwenden ein vortrainiertes Sprachmodell – ein großes neuronales Netzwerk, das anhand großer Mengen von Textdaten trainiert wurde, wobei in der Regel unüberwachte Lernverfahren zum Einsatz kommen. Auf der Grundlage dieses Datenkorpus kann ein Chatbot anhand statischer Wahrscheinlichkeiten Antworten auf die von einem Menschen gestellten Fragen erstellen.
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz, der ebenfalls Algorithmen verwendet, die anhand der bereitgestellten Daten erstellt werden. Mithilfe dieser Algorithmen wird eine Maschine – z. B. eine Anwendungssoftware oder Komponenten – leistungsfähiger. In der Automobilelektronik beispielsweise hilft maschinelles Lernen, Verkehrszeichen zu erkennen und zu verstehen.
Deep Learning ist ein Teilbereich des maschinellen Lernens, der komplexere Algorithmen und neuronale Netzwerke verwendet, die den Aufbau der Neuronen im Gehirn simulieren.
Lösung von musterbasierten Problemen mithilfe von maschinellem Lernen
Maschinelles Lernen löst Probleme, für die Muster verwendet werden können. Die Entwickler oder die Organisation müssen eine große Menge an Beispieldaten sammeln – zum Beispiel Verkehrsschilder. Der Algorithmus wandelt die unstrukturierten Informationen aus einem Datensatz in ein standardisiertes Format um.
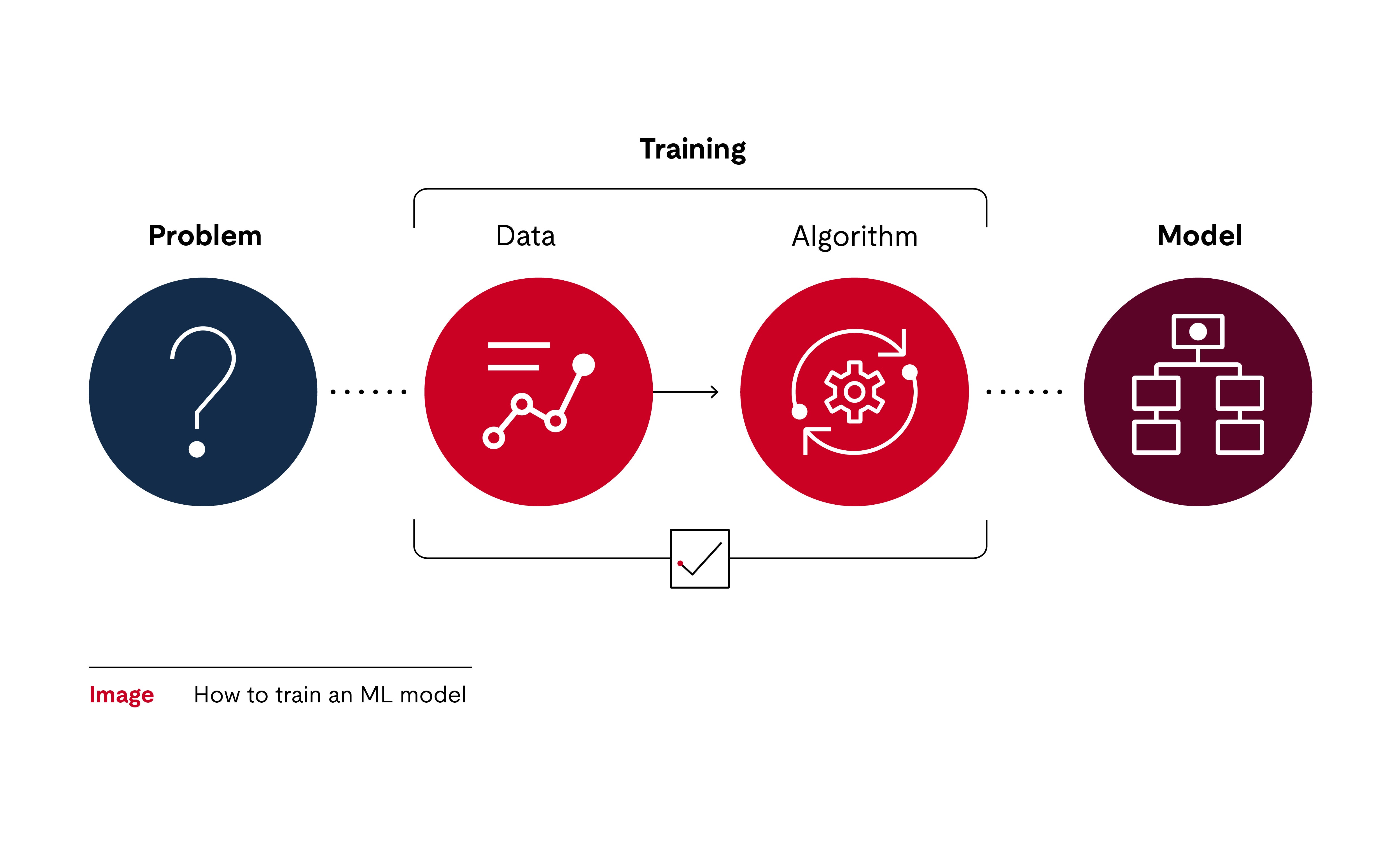
Was das maschinelle Lernen angeht, ist es wichtig zu verstehen, dass kein Mensch dieses Software-Artefakt programmiert hat. Der Algorithmus optimiert und verfeinert sich durch den Trainingsprozess. Durch diesen Prozess versucht er, das Verhalten anzunähern und anhand von Beispielen sinnvolle Muster zu lernen. Es gibt nicht nur einen Algorithmus, sondern unzählige Möglichkeiten, das Ziel zu erreichen. Der Entwickler für maschinelles Lernen wählt den für die weitere Verwendung am besten geeigneten Algorithmus aus.
Der Algorithmus entwickelt unabhängig vom Datensatz Anweisungen. Dies wird als maschinelles Lernen bezeichnet, da der Algorithmus selbst lernt, wie er die gegebenen Daten in Informationen strukturieren kann. Damit das Training zum gewünschten Ergebnis führt, wird dem Algorithmus mitgeteilt, wie er die Umgebung aus technischer Sicht interpretieren soll. In unserem Beispiel der Verkehrszeichenerkennung kann er Muster erkennen, indem er die Farbverteilung analysiert und die wahrscheinlichsten Verkehrszeichennamen zuordnet.
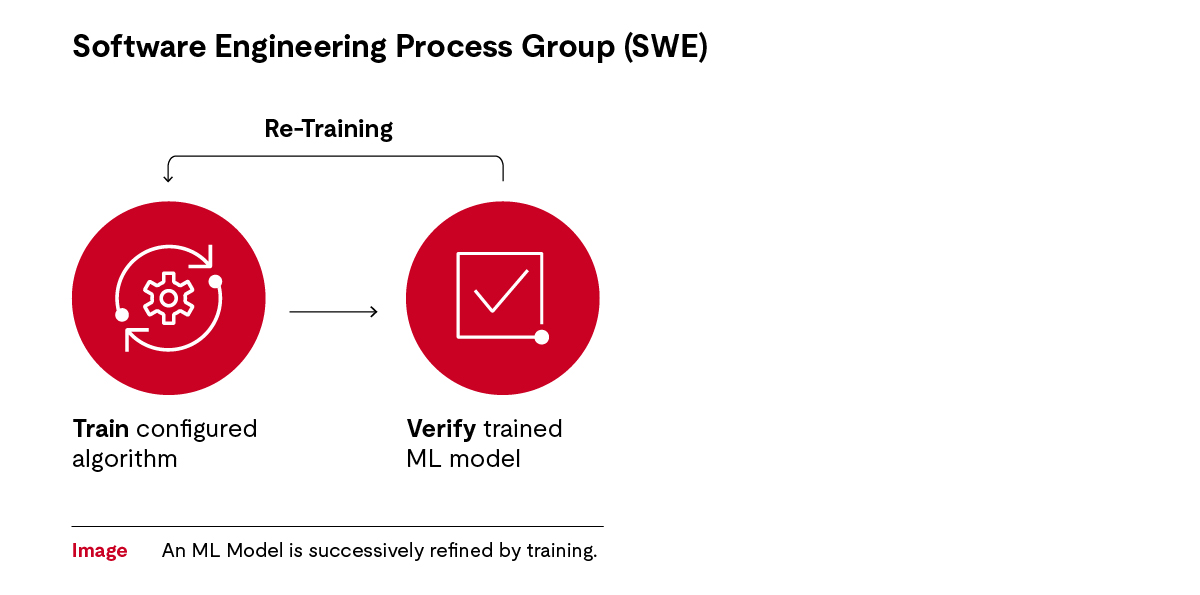
Dieses Training ist ein sich wiederholender Prozess – ein Forschungs- und Entwicklungsansatz (R&D) mit Versuch-und-Irrtum-Zyklen. Entwickler für maschinelles Lernen überprüfen regelmäßig, ob der Algorithmus die Trainingsdaten strukturieren und sie den Namen der Verkehrsschilder zuordnen kann. Der Entwickler für maschinelles Lernen verfeinert anschließend den Algorithmus mit zusätzlichem Trainingsmaterial und wiederholt den Prozess, bis ein solides Modell entsteht. Der Entwickler setzt den Algorithmus den Daten aus und überprüft die Ausgaben.
Das Modell ist das Asset, das alle Informationen enthält. Dieses Modell kann dann in der Anwendungssoftware implementiert werden. In unserem Beispiel enthält das Modell einen Entscheidungsbaum, der uns sagt, wie die Bildfarben mit den verschiedenen Verkehrszeichen verknüpft sind.
Das Modell wird mit einem unabhängigen Datensatz überprüft, um sicherzustellen, dass das Modell nicht anhand der Daten, sondern anhand der möglichen Situationen in der tatsächlichen Umgebung trainiert wurde.
Da die Software nicht von einem Menschen geschrieben wurde, ist sie eine Blackbox. Der Algorithmus liefert ein Ergebnis – das Modell. Allerdings ist dieses Modell in seiner Struktur nicht mit vertretbarem Aufwand zu verstehen. Wir stehen also vor der Herausforderung, zuverlässige Software für ein sicherheitskritisches System zu schreiben, ohne zu wissen, wie es funktioniert. Dies ist aus Sicht der Qualitätssicherung inakzeptabel.
Aufgrund des Entwicklungsansatzes des maschinellen Lernens stehen wir mit der Einführung von maschinellen Lernmodellen in der Automobilsoftware und im Backend im Hinblick auf Qualität, funktionale Sicherheit und Cybersicherheit vor neuen Herausforderungen.
Konventionelle Verfahren, die von Standards wie Automotive SPICE® bereitgestellt werden, funktionieren nicht in Verbindung mit maschinellem Lernen. Bei einer herkömmlichen Entwicklung beschreiben Sie die Anforderungen – was die Software leisten soll. Dann entwerfen Sie die Architektur – die Organisation Ihrer Software, um diese Funktionen bereitzustellen. Zum Schluss legen Sie für jede Einheit die Details fest, die im Code implementiert werden müssen. Entlang dieser Gliederungsebenen führen Sie eine Reihe von Tests durch.
Beim maschinellen Lernen gibt es keine derartigen formalisierten Tests. Sobald der Entwickler mit dem Ergebnis, das die zuvor festgelegten Kriterien erfüllt, zufrieden ist, wird der Algorithmus getestet und freigegeben. Die Überprüfung und das Testen des maschinellen Lernens hängt daher vor allem von der Kennzeichnung der Daten, dem Training, dem Anti-Bias und der Sicherstellung, dass die wichtigsten Leistungsindikatoren (KPIs) erfüllt werden, ab.
Aus Sicht der Qualitätssicherung kann man sich den Ausbildungs-, Verifikations- und Testprozess wie die Schichten einer Zwiebel vorstellen, um die festgelegte Reihenfolge und die Abhängigkeiten zu verdeutlichen.
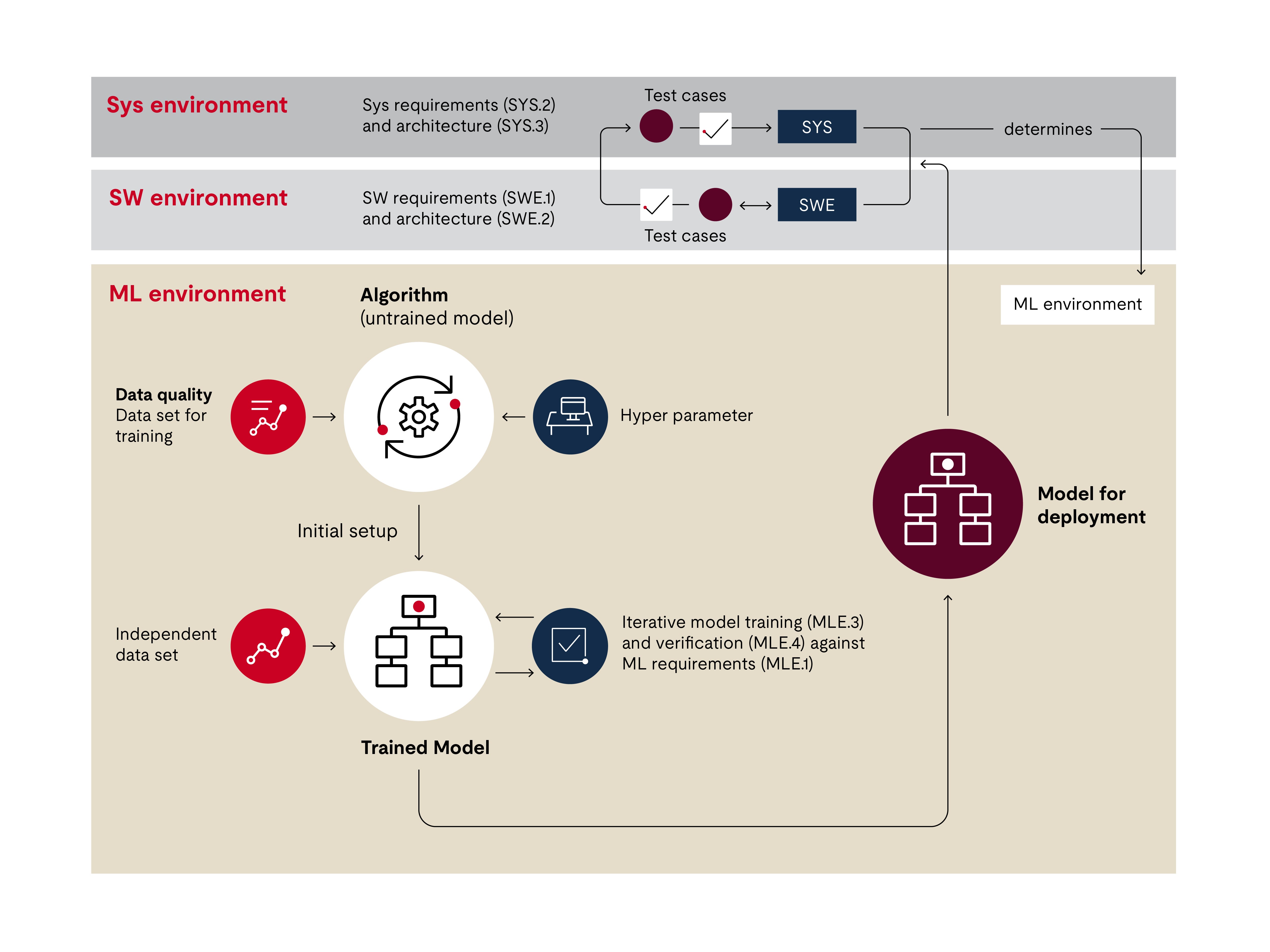
Die innere Schicht der Zwiebel ist der Algorithmus. Dieser wurde von dem Entwickler für maschinelles Lernen für die gewünschte Funktionalität konfiguriert. Diese Anpassung kann z. B. die Anzahl der neuronalen Verbindungen oder Knoten steuern. Wenn eine Aktualisierung des Algorithmus erforderlich ist, sind ein neues Training und eine neue Überprüfung notwendig. Zusammen bilden die beiden Ebenen das trainierte Modell. Die Prüfung des Modells wirkt sich dann auf diese beiden Ebenen aus.
Da das Modell auf Trainingsdaten basiert, ist die Datenqualität ein zentrales Thema. Im Zwiebeldiagramm sehen wir, dass sich ein separater Prozess mit den Daten befasst.
Anwendung des maschinellen Lernmodells für Automotive SPICE®
Prozesse für Software-Artefakte, die durch maschinelles Lernen erstellt werden, sind Softwareentwicklungsprozesse. Daher stützt sich der Automotive SPICE® Standard auf die Prozesse der Softwareentwicklung. Im Anforderungsprozess (SWE.1) werden die Anforderungen an die zu erstellende Software formuliert; dies ist bei jeder Software der Automobilelektronik der Fall. Zu diesem Zweck werden die relevanten Systemanforderungen in eine Reihe von Softwareanforderungen umgewandelt, von denen einige dann Softwareartefakte betreffen, die mithilfe von maschinellem Lernen erstellt werden sollen. Die Softwarearchitektur als Ergebnis des SW-Architekturdesigns (SWE.2) regelt, welche das sind.
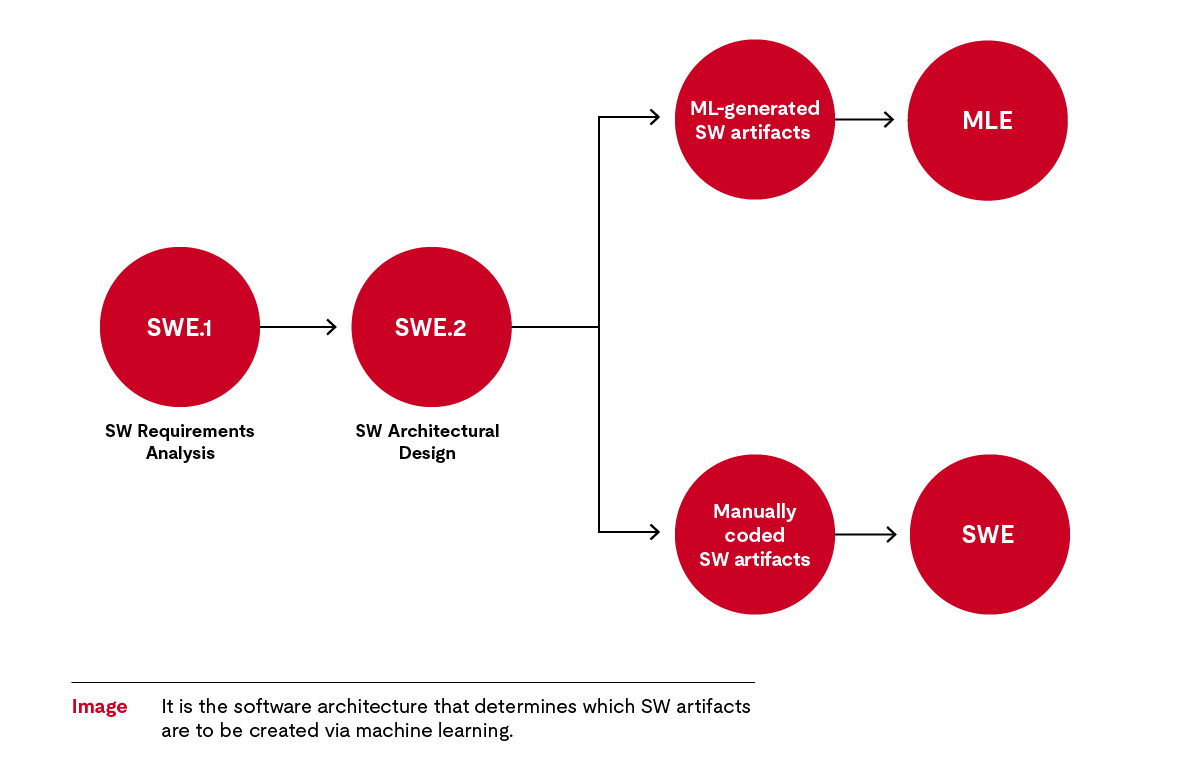
Beim maschinellen Lernen sollen die Software-Artefakte durch einen Algorithmus erzeugt werden, so dass wir spezielle Verfahren benötigen, die den klassischen Software-Detailentwurf ersetzen.
Im folgenden Diagramm ist oben links im V der Prozess der Anforderungsanalyse durch maschinelles Lernen (MLE.1) dargestellt. Dieses Verfahren soll aus den Softwareanforderungen die spezifischen Anforderungen für maschinelles Lernen ermitteln.
Darauf folgt die Architektur für maschinelles Lernen (MLE.2). Dieser Prozess betrifft die Architektur des maschinellen Lernens, die das Training und die Erstellung des Algorithmus unterstützt, sowie andere notwendige Software, wie z. B. Pre- und Post-Processing-Software.
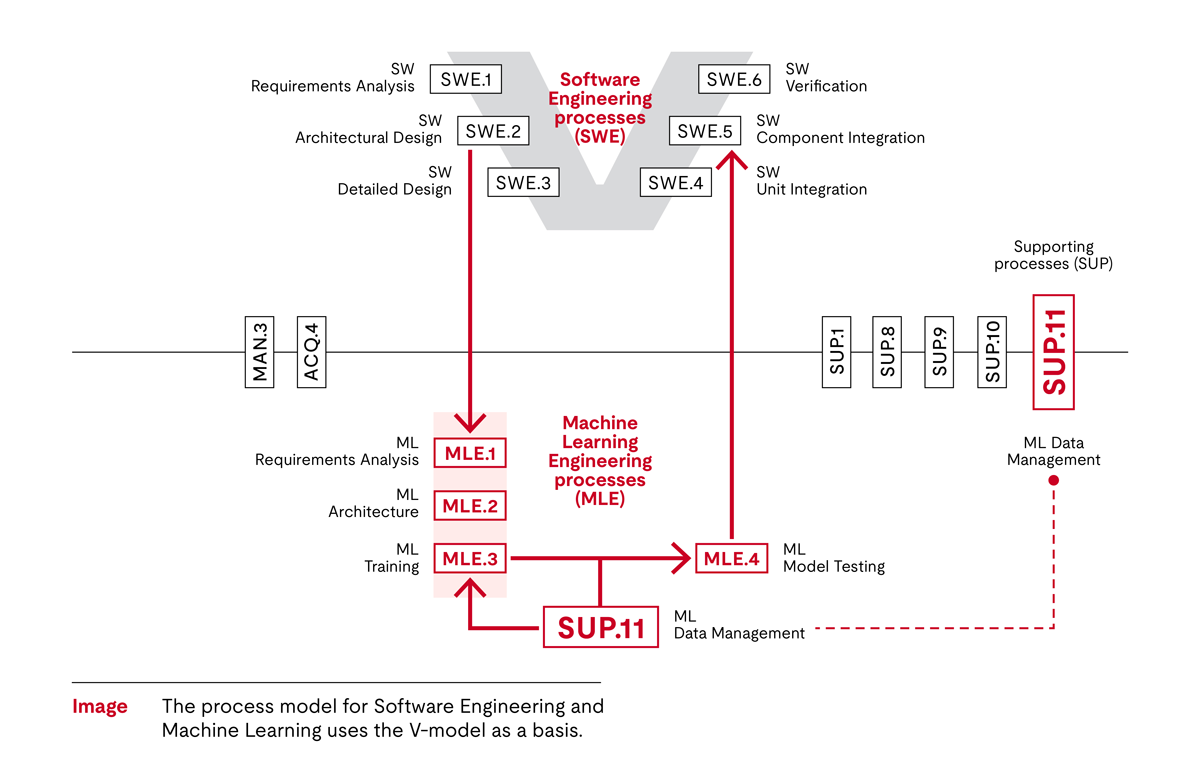
Auf der rechten Seite des V finden Sie das Training des Algorithmus. Entscheidend ist, dass das Modell nicht nur leistungsfähig ist, sondern vor allem, dass es die vorgegebenen Anforderungen erfüllt (MLE.3). Wie bereits erwähnt, handelt es sich bei dem Training um einen systematischen Ansatz, der auf Versuch und Irrtum beruht.
Beim Testen muss sichergestellt werden, dass sowohl das trainierte maschinelle Lernmodell als auch das implementierte maschinelle Lernmodell die Vorgaben der Anforderungen an das maschinelle Lernen (MLE.4) erfüllen. Wir unterscheiden zwischen einem trainierten Modell, das verifiziert wurde, und dem eingesetzten Modell, das in der eigentlichen Software des Systems verwendet werden kann.
Beim Software-Integrationstest (SWE.5) werden dann alle Artefakte integriert und gemeinsam getestet. Hier kommen alle Artefakte zusammen, unabhängig davon, ob sie auf herkömmliche Weise kodiert oder mit einem maschinellen Lernansatz trainiert wurden.
Dies gilt jedoch nicht für die Datenqualität. Beim neuen Support-Prozess, dem Datenmanagement für maschinelles Lernen (SUP.11) werden die für das maschinelle Lernen relevanten Daten im Einklang mit den Anforderungen an maschinelle Lerndaten festgelegt und die Integrität der Daten sichergestellt.
Das Datenmanagement ist eine sehr komplexe Aufgabe, mit der sich oft große Gruppen innerhalb einer Organisation befassen. Daher gibt es ein separates Modell zur Bewertung des Datenmanagementprozesses.
In Automotive SPICE® v4.0 wird das maschinelle Lernen Teil des Standards. In Verbindung mit der konventionell entwickelten Software kann die Entwicklung des maschinellen Lernens nun unter Qualitätsgesichtspunkten erfolgen. Dies ist auch eine gute Grundlage für funktionale Sicherheit und Cybersicherheit.
Weshalb Sie sich für UL Solutions Software Intensive Systems zur Unterstützung von Automotive SPICE® entscheiden sollten?
Im Rahmen unserer Strategie zur systematischen Verbesserung der Entwicklungsprozesse im Bereich der Automobilelektronik ist UL Solutions Software Intensive Systems offizieller Lizenznehmer von Automotive SPICE®, einer Marke des Verbands der deutschen Automobilindustrie (VDA QMC).
Wir können Automobilhersteller (OEMs) und -zulieferer dabei unterstützen:
- Innerhalb von wichtigen Entwicklungsprozessen das erforderliche Fähigkeitsniveau zu erreichen.
- Bestehende Arbeitsabläufe und Methoden systematisch zu verbessern.
- Den Status von Prozessverbesserungen durch formale Bewertungen und Gap-Analysen zu bewerten.
- Die Anforderungen von Automotive SPICE® im Einklang mit Sicherheit, funktionaler Sicherheit und agilen Methoden zu erfüllen.
- Ausbildung von Mitarbeitern und Prüfern.
X
Kontaktieren Sie unser Team
Danke für Ihr Interesse an unseren Produkten und Services. Teilen Sie ein paar Informationen mit uns, damit wir Sie mit der richtigen Person zusammenbringen können.
Bitte warten…
Verbleibende Zeichen