Guide zu C/C++: Software für Automobil-Bereich
April 22, 2021 | 8:00 am
CDT
Dies ist der zweite von zwei Beiträgen, in denen wir mehrere praktische Open-Source-Tools vorstellen, mit denen Sie Ihre Kompilierzeit verkürzen können. Der Schwerpunkt liegt dabei auf parallelen Builds mit icecream.
Ab einer gewissen Projektgröße werden die Kompilierungszeiten lästig. Deshalb brauchen Sie effektive Möglichkeiten, Ihre Produktivität zu maximieren, indem Sie die Kompilierungszeiten soweit minimieren, dass es nur noch zu zwischenzeitlichen Verzögerungen kommt.
Als Ingenieur suchen Sie wahrscheinlich Tools, um dieses Problem zu lösen. Genau darum geht es in dieser Artikelserie. In Teil 1 haben wir den Einsatz von cache beleuchtet, um Buildartefakte zu speichern, damit der Compiler nicht immer wieder das Gleiche tun muss. In diesem Artikel geht es um die Nutzung Ihrer bestehenden Hardwareinfrastruktur durch die dynamische Auslagerung von Buildaufträgen auf mehrere Rechner.
Verteilte Kompilierung
Die Grundidee der verteilten Kompilierung ist folgende: Während Sie sich mit der Entwicklung der Software beschäftigen, ist Ihr Rechner – bis auf sporadische Aktivitätsspitzen, wenn Sie auf „Build“ klicken – meist wenig ausgelastet. Das Potenzial zur Parallelisierung ist hoch, da Quellmodule in der Regel unabhängig voneinander kompiliert werden können. So können Sie die ungenutzten Befehlszyklen der Systeme Ihrer Kollegen nutzen und die Kompilierungsarbeit aufteilen.
Der bekannteste Open-Source-Vertreter eines verteilten Kompiliersystems ist distcc. Dies besteht aus einem Serverdaemon, der Buildaufträge über das Netzwerk annimmt, und einem Compilerwrapper, der die Aufträge an die im Netzwerk verfügbaren Buildknoten verteilt. Obwohl die Architektur von distcc relativ einfach und überschaubar ist, gibt es auch Nachteile:
- Die Liste der teilnehmenden Buildknoten ist statisch und muss im Voraus bekannt sein. Sie wird in Form einer Umgebungsvariable definiert. Wenn ein Knoten hinzugefügt oder entfernt wird, muss die entsprechende Umgebungsvariable auf allen Clients geändert werden.
- Der Planungsalgorithmus ist relativ naiv und ist von sich aus nicht in der Lage, leistungsstärkere Buildknoten gegenüber schwächeren vorzuziehen.
- Crosskompilieren ist nicht trivial, denn die richtige Version der Toolchainversion muss auf allen Buildknoten vorinstalliert sein. Eine heterogene Infrastruktur (z. B. unterschiedliche Linuxdistributionen auf unterschiedlichen Rechnern) kann problematisch sein.
Deshalb stellen wir mit icecream eine fortschrittliche Alternative zu distcc vor, die mehrere interessante Funktionen bietet.
Icecream: ein verteiltes Kompiliersystem
Icecream ist ein von SUSE initiiertes und gepflegtes Open-Source-Projekt. Es begann als Abspaltung von distcc, aber die beiden Codebasen haben sich seitdem stark voneinander entfernt. Im Gegensatz zur Peer-to-Peer-Architektur von distcc ist eine icecream-Kompilierfarm um einen zentralen Server herum aufgebaut. Auf dem Server läuft ein Schedulerdaemon, der die eingehenden Kompilieraufträge an die verfügbaren Buildknoten verteilt. Buildknoten registrieren und deregistrieren sich dynamisch beim Scheduler, so dass eine manuelle Pflege der statischen Liste potenzieller Kompilierungshosts nicht notwendig ist.
Die Komponente, die neue icecream-Aufträge auf der Clientseite erstellt und sie an den Scheduler weiterleitet, heißt icecc. Durch ihre Implementierung als Compilerwrapper kann sie leicht in jedes bestehende Buildsystem integriert werden, einschließlich CMake, Autotools und Makefiles. Icecream-Aufträge befinden sich auf der Granularitätsebene von Modulen, d. h. jeder Auftrag beinhaltet die Kompilierung einer einzelnen Quelldatei (.c/.cpp) in eine Objektdatei (.o). Das abschließende Linking, bei dem die gesammelten Objektdateien zu einer ausführbaren Binärdatei oder Bibliothek zusammengefügt werden, erfolgt immer lokal.
Das große Ganze
Icecream wird typischerweise mit folgenden Komponenten verwendet:
- Auf einem zentralen Server: eine Instanz des icecc-Schedulerdaemons.
- Auf jedem an der icecream-Farm beteiligten Buildknoten: eine Instanz des iceccd-Daemons. Der Server kann, muss aber nicht, beinhaltet sein.
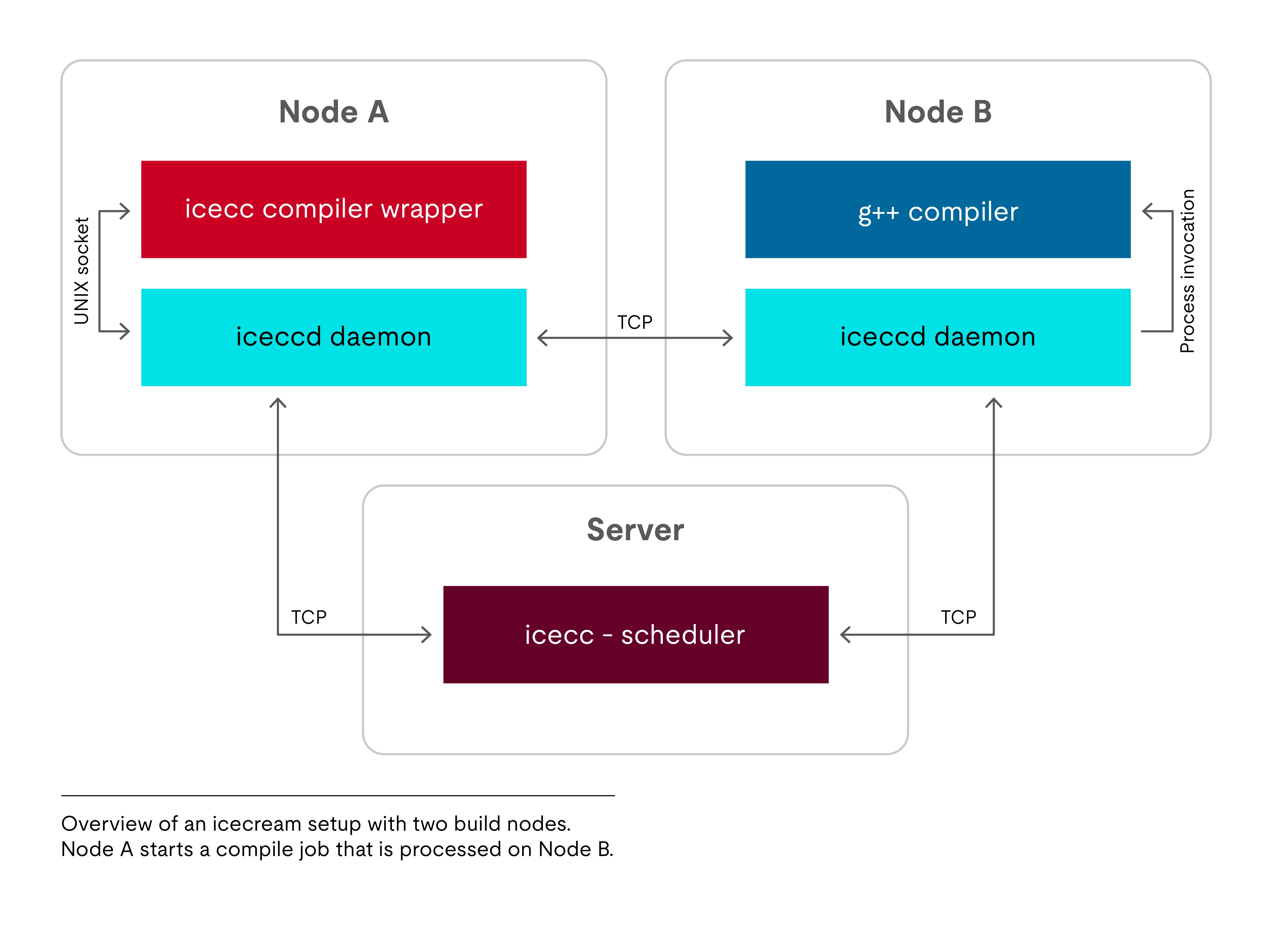
In der Abbildung rechts sehen Sie, wie die verschiedenen icecream-Komponenten in einem Setup mit zwei Buildknoten interagieren. Ihre Aufgaben teilen sich folgendermaßen auf:
- Der Compilerwrapper erstellt neue Kompilieraufträge und übergibt sie dann an den lokalen Daemon. Anschließend wartet er auf das Ergebnis.
- Der Daemon nimmt Aufträge entgegen und verarbeitet sie entweder lokal, oder leitet sie an einen anderen Daemon weiter, je nachdem, was der Scheduler empfiehlt.
- Welcher Auftrag von wem bearbeitet werden soll, entscheidet der Scheduler.
Im Folgenden geht es darum, was passiert, wenn der Benutzer auf Knoten A icecc ausführt, um eine C++-Quelldatei zu kompilieren.
So funktioniert icecream
Wenn icecc auf Knoten A ausgeführt wird, leitet es zunächst die Quelldatei durch den Präprozessor; so werden die .cpp-Datei und die zugehörigen Header zu einem einzigen, in sich geschlossenen Textstrom geglättet. Für den schwierigen Teil – die Übersetzung des Quellcodes in Maschinencode – beansprucht icecc dann die Hilfe des lokalen Daemon.
An diesem Punkt kann der iceccd-Daemon entweder die Anfrage lokal bearbeiten oder sie an einen anderen Host weiterleiten. Diese Entscheidung wird nicht vom Daemon selbst, sondern von einer zentralen Instanz getroffen, die über umfassende Informationen über den globalen Zustand der Buildfarm verfügt: dem Scheduler. Der Scheduler behält die Übersicht über die Anzahl der aktiven Aufträge sowie darüber, welche Knoten im Netz vorhanden sind und wie sie in der Vergangenheit gearbeitet haben. Diese Informationen bilden die Entscheidungsgrundlage. In unserem Beispiel weist der Scheduler den Daemon an, den Auftrag an Knoten B weiterzuleiten.
Der Daemon auf Knoten A sendet also den vorverarbeiteten Quellcode zusammen mit der benutzerdefinierten Compilerbefehlszeile an seine Gegenstelle auf Knoten B. Außerdem fasst er die lokale Buildtoolchain in einem Tarball zusammen und übergibt diesen dann an Knoten B (sofern dort nicht bereits eine Kopie zwischengespeichert wurde). Der Daemon auf dem Zielrechner entpackt die Buildumgebung in ein temporäres chroot-Verzeichnis. Anschließend führt er den Compiler in der chroot-Umgebung aus und schickt das Ergebnis zurück. Wenn die Kompilierung erfolgreich war, besteht die Antwort aus einem „Daumen hoch“ oder einem „Daumen runter“, einem Kompilierungslog (wenn der Compiler Warnungen und/oder Fehler erzeugt hat) und der resultierenden .o-Datei.
Arbeiten in einer heterogenen Umgebung
Durch die bereits erwähnte Übertragung von Tarballs der Buildumgebung sind die Buildaufträge weitgehend in sich geschlossen. Dies stellt insbesondere sicher, dass es keine versteckten Abhängigkeiten zwischen den icecream-Knoten gibt: Da icecream automatisch für die Verteilung der richtigen Toolchain sorgt, ist es beispielsweise nicht notwendig, dass überall eine bestimmte Compilerversion vorhanden ist.
Daher braucht icecream keine auf allen Buildknoten identische, lokal installierte Toolchain. Genau genommen braucht es überhaupt keine lokal installierte Toolchain (auf reinen Serfknoten). Außerdem ist der Einsatz von icecream in einer heterogenen Umgebung einfach, wenn dort verschiedene Rechner mit unterschiedlichen Betriebssystemen oder verschiedenen Versionen laufen. Die einzige Bedingung ist, dass alle teilnehmenden Knoten dieselbe Hardwarearchitektur nutzen und auf derselben Betriebssystem-Familie basieren, d. h. eine Kombination von x86_64 mit ARM64 oder von Linux mit macOS ist nicht möglich.
Wichtige Sicherheitswarnung
Bevor wir erklären, wie man icecream einrichtet und verwendet, müssen wir mögliche Sicherheitsaspekte erörtern. Icecream selbst bietet keinen Authentifizierungsmechanismus, so dass jeder jedem beliebige Buildumgebungs-Tarballs senden kann. Dies macht icecream im Wesentlichen zu einem Remote-Code-Ausführungsdienst. Das Risiko wird dadurch etwas abgeschwächt, dass icecream die Buildtoolchain als Benutzer ohne Berechtigungen in einer chroot-Umgebung ausführt. Denken Sie jedoch daran, dass chroot allein nicht als vollwertiger Sicherheitsmechanismus dient (im Gegensatz zu FreeBSD Jails).
Daher sollten die Knoten nur unternehmensinternen icecream-Datenverkehr akzeptieren. Die Firewall Ihres Unternehmens sollte also wenigstens alle eingehenden icecream-Pakete von außerhalb des Perimeters ablehnen.
Für stärkere Sicherheitsgarantien und eine obligatorische Authentifizierung empfehlen wir Ihnen, ein dediziertes VPN zwischen Ihren Rechnern einzurichten. Dafür kommen zum Beispiel WireGuard oder OpenVPN in Frage. Seit icecream 1.3 können Sie den gesamten icecream-Verkehr durch das VPN leiten. Dazu müssen Sie den icecream-Daemon und dem Scheduler anweisen, nur an der spezifischen Netzwerkschnittstelle zu lauschen, die mit dem VPN verbunden ist.
Tutorial: Wie man icecream im Projekt verwendet
Um icecream zu implementieren, wählt man im ersten Schritt einen designierten Server, auf dem die Schedulerkomponente gehostet wird. Wählen Sie einen Rechner, der – zumindest während der Bürozeiten – immer eingeschaltet und erreichbar ist. Im Folgenden wird dieser Host als my-icecream-server bezeichnet.
Als nächstes brauchen Sie einen Namen für Ihre Farm. In den folgenden Beispielen verwenden wir my-icecream-network als generischen Platzhalter.
Installation von icecream
Da icecream bereits im Paketrepository Ihrer Linuxdistribution enthalten ist, müssen Sie nur noch den Paketmanager starten. Alle Komponenten von icecream sind in der Regel in einem Paket gebündelt. Die Installation auf dem Server und auf den Clients ist deshalb identisch.
In Debian/Ubuntu:
$ sudo apt install icecc
In Fedora/CentOS/RHEL:
$ sudo dnf install icecream
Als nächstes editieren wir die Konfigurationsdatei von icecream. Der Prozess ist weitgehend gleich, unabhängig davon, ob Sie den Server oder einen Client konfigurieren. Auf die Unterschiede wird weiter unten eingegangen.
Für Server und Clients identische Konfigurationsschritte
Der Pfad und der Inhalt der Konfigurationsdatei variieren von einer Linuxdistribution zur anderen geringfügig. Auf jeden Fall handelt es sich bei der Datei normalerweise um ein kleines Shellskript, das mehrere Variablen definiert.
In Debian/Ubuntu finden Sie die Konfigurationsdatei unter /etc/icecc/icecc.conf. Sie sollten die folgenden Variablen setzen:
ICECC_NETNAME="my-icecream-network"
ICECC_SCHEDULER_HOST="my-icecream-server"
In Fedora/CentOS/RHEL befindet sich die Datei unter /etc/sysconfig/icecream und die Konfigurationsvariablen werden anders vorangestellt:
ICECREAM_NETNAME="my-icecream-network"
ICECREAM_SCHEDULER_HOST="my-icecream-server"
Was bewirken diese beiden Einstellungen?
-
In der ersten Zeile wird ein Netzwerkname angegeben. Dies ist nützlich, wenn mehrere unabhängige Buildfarmen innerhalb desselben physischen Netzes koexistieren sollen.
-
Die zweite Zeile zeigt Ihrer iceccd-Instanz den Rechner an, auf dem der Scheduler zu finden ist. Wenn der Entwicklungsrechner und der Buildserver sich im gleichen Subnetz befinden, ist dies meist überflüssig, weil sie sich über zeroconf finden können.
Wenn Sie die Konfigurationsdatei gespeichert haben, starten Sie den icecream-Daemon neu, um die neuen Einstellungen zu übernehmen:
$ sudo systemctl restart iceccd.service
Der nächste Schritt hängt davon ab, ob Sie den Server oder einen Client einrichten.
Serverspezifische Konfiguration
Bei der Serverkonfiguration muss die Schedulerkomponente aktiviert sein und ihre Konfiguration muss neu geladen werden:
$ sudo systemctl enable icecc-scheduler.service
$ sudo systemctl restart icecc-scheduler.service
Ihr Server ist nun betriebsbereit und der Scheduler kann eingehende Jobanfragen den Knoten zuweisen.
Clientspezifische Konfiguration
Der Scheduler sollte immer nur auf einem Rechner auf einmal laufen. Wenn mehrere Scheduler versuchen, dieselben Clients zu bedienen, kann dies icecream verwirren. Das führt dazu, dass Buildrechner zufällig verschwinden und wieder auftauchen. Sie sollten deshalb auf allen Rechnern – mit Ausnahme des vorgesehenen Schedulerservers – den Schedulerdaemon anhalten und sicherstellen, dass er nicht versehentlich wieder gestartet wird:
$ sudo systemctl stop icecc-scheduler.service
$ sudo systemctl disable icecc-scheduler.service
Nun registrieren sich die iceccd-Daemons auf Ihren Clients beim Scheduler und sind bereit, Aufträge anzunehmen.
Was bei Konnektivitätsproblemen zu tun ist
Wenn auf Ihrem Rechner eine paketfilternde Firewall aktiviert ist, stellen Sie sicher, dass die folgenden Ports offen sind:
-
Schedulerserver: TCP 10245, TCP 8765, TCP 8766, UDP 8765
-
Entwicklungsrechner: TCP 10245
So aktivieren Sie icecream in Ihrem Projekt
Genau wie ccache, liefert icecream mehrere symbolische Links in einem Systemverzeichnis. Diese Links sind nach den gängigen Binärsystemen (gcc, clang, c++ usw.) benannt, verweisen aber auf den icecream-Compilerwrapper. Um icecream zu aktivieren, stellen Sie dieses Verzeichnis Ihrer PATH-Umgebungsvariable voran, damit nicht die reguläre Compiler-Binärdatei aufgerufen wird, sondern der Wrapper. Kopieren Sie die folgende Zeile in Ihr Terminal oder fügen Sie sie zu Ihrer Projektkonfiguration hinzu. Beachten Sie, dass das icecream-Verzeichnis an erster Stelle stehen muss, weil das System den PATH von links nach rechts durchsucht.
In Debian/Ubuntu:
$ export PATH="/usr/lib/icecc/bin:$PATH"
In Fedora/CentOS/RHEL:
$ export PATH="/usr/libexec/icecc/bin:$PATH"
Um Ihre Buildfarm optimal zu nutzen, müssen Sie Ihr Buildsystem wahrscheinlich anweisen, mehr parallele Aufträge als üblich zu erzeugen. Standardmäßig erstellen die meisten Buildsysteme entweder überhaupt keine parallelen Aufträge oder sie starten so viele Aufträge, wie (logische) Prozessorkerne auf dem lokalen Rechner verfügbar sind. Es werden mehr benötigt, um die Buildfarm zu versorgen!
Sie müssen nun einen guten Kompromiss finden: Bei zu wenigen Aufträgen verschenken Sie Parallelitätspotenzial; bei zu vielen Aufträgen leidet Ihr Entwicklungsrechner unter übermäßigem Speicherdruck. Meiner persönlichen Erfahrung nach sind 64 Aufträge für Rechner mit 16-32 GiB RAM angemessen.
Ihr Buildbefehl sollte also in etwa so aussehen:
$ make -j64
So sparen Sie mit icecream Zeit
Die tatsächliche Leistung von icecream hängt von vielen verschiedenen Faktoren ab. Sie wird stark von der verfügbaren Rechenleistung, der jeweiligen Systemlast, der Netztopologie und anderen Faktoren beeinflusst. Außerdem ist der Scheduler etwas unstet und triff manchmal seltsame Entscheidungen.
Mit der Infrastruktur meines derzeitigen Entwicklungsprojekts kann eine ausreichend große icecream-Farm (sechs relativ leistungsfähige Rechner) die Geschwindigkeit maximal um den Faktor zwei bis drei erhöhen. Das ist zwar alles andere als eine lineare Skalierung, spart aber dennoch viel Zeit. Interessanterweise funktioniert das auch dann noch ziemlich gut, wenn alle von zu Hause aus arbeiten und nur über VPN verbunden sind.
Stellen Sie sich auf erhebliche Geschwindigkeitsschwankungen ein, da Ihre Teammitglieder immer nur ihre ungenutzten Ressourcen zur Verfügung stellen. Wenn die verfügbaren Ressourcen nicht ausreichen, können Sie vielleicht ausgemusterte, aber noch brauchbare Hardware als zusätzliche Buildserfs in Ihre Farm integrieren.
Liveüberwachung mit icemon
Das GUI-Dienstprogramm icemon, das in einem separaten Paket erhältlich ist, bietet einen farbigen Echtzeitüberblick über den aktuellen Zustand Ihres icecream-Clusters.
In Debian/Ubuntu:
$ sudo apt install icecc-monitor
In Fedora/CentOS/RHEL:
$ sudo dnf install icemon
Icemon bietet viele verschiedene Ansichten, die den aktuellen Zustand Ihres Buildclusters visualisieren. Die Standardansicht ist die Sternansicht (siehe oben), in der die Buildknoten um den zentralen Scheduler angeordnet sind. Aktive Aufträge werden als Ringe um die Buildknoten herum dargestellt. Wenn Sie auf „Build“ klicken, können Sie beobachten, wie eine Art Blumenstrauß zum Leben erwacht.
Icemon holt sich alle angezeigten Informationen durch Abfrage des Schedulers. Es versucht, den Scheduler selbst zu finden, aber das funktioniert oft nicht auf Anhieb. Wenn Sie vor dem Aufruf von icemon die Umgebungsvariable USE_SCHEDULER auf den Hostnamen des Servers setzen, weisen Sie icemon explizit an, wo sich der Scheduler befindet:
$ USE_SCHEDULER=my-icecream-server icemon
Fazit
Mit icecream haben Sie ein nützliches Tool, um aus Ihrem Büro eine verteilte Kompilierfarm zu machen. Dadurch, dass Kompilieraufträge auf mehrere Rechner verteilt werden und gleichzeitig abgearbeitet werden, verkürzen sich Erstellungszeiten und die Produktivität wird gesteigert. Auch ccache, das wir in Teil 1 behandelt haben, kann für gleichzeitiges Caching und Verteilen mit icecream kombiniert werden.
X
Kontaktieren Sie unser Team
Danke für Ihr Interesse an unseren Produkten und Services. Teilen Sie ein paar Informationen mit uns, damit wir Sie mit der richtigen Person zusammenbringen können.
Bitte warten…
Verbleibende Zeichen