Measuring Real-Time Operating System Performance – Part II: Comparing FreeRTOS vs. Zephyr
September 22, 2022 | 8:00 am
CDT
The first post in this two-part series covered how you can port RTOSBench, a benchmark suite for kernel services, to FreeRTOS and Zephyr. Now, it is time to execute tests from RTOSBench on both operating systems and analyze the results.
All tests were executed on a STM32F429ZIT6, running each test scenario 1000 times. This approach allows us to understand execution time consistency.
Kernel Configuration
Before we analyze the test results, we first have to talk about the configuration of both operating systems. At the time of writing both posts, the most current versions are FreeRTOS v10.4.4 and Zephyr v2.6.0. We also must ensure the operating systems under test are configured as similar as possible. Otherwise, we will not end up with comparable results. Below are excerpts of the relevant kernel configuration parameters I will use:
FreeRTOS Configuration
/* Reduce tick rate so there are no timer interrupts during benchmarks */
#define configTICK_RATE_HZ ((TickType_t)20)
/* Completely disable asserts */
#define configASSERT( x )
/* Enable required data structures */
#define configUSE_MUTEXES 1
#define configUSE_RECURSIVE_MUTEXES 1
#define configUSE_COUNTING_SEMAPHORES 1
Zephyr Configuration
# Reduce tick rate so there are no timer interrupts during benchmarks
CONFIG_SYS_CLOCK_TICKS_PER_SEC=20
CONFIG_TICKLESS_KERNEL=n
# Disable Idle Power Management
CONFIG_PM=n
# Reduce memory/code foot print
CONFIG_BT=n
# Completely disable asserts
CONFIG_FORCE_NO_ASSERT=y
# Stack Protection defaults to on since Zephyr v2.5.0. This is a significant
# overhead during benchmarks. FreeRTOS does not enable stack protection by
# default. So we turn it off here to get cleaner results.
CONFIG_HW_STACK_PROTECTION=n
CONFIG_COVERAGE=n
# Enable timing subsystem
CONFIG_TIMING_FUNCTIONS=y
# Allow RTOSBench to allocate interrupts during runtime
CONFIG_DYNAMIC_INTERRUPTS=y
Analyzing the Results
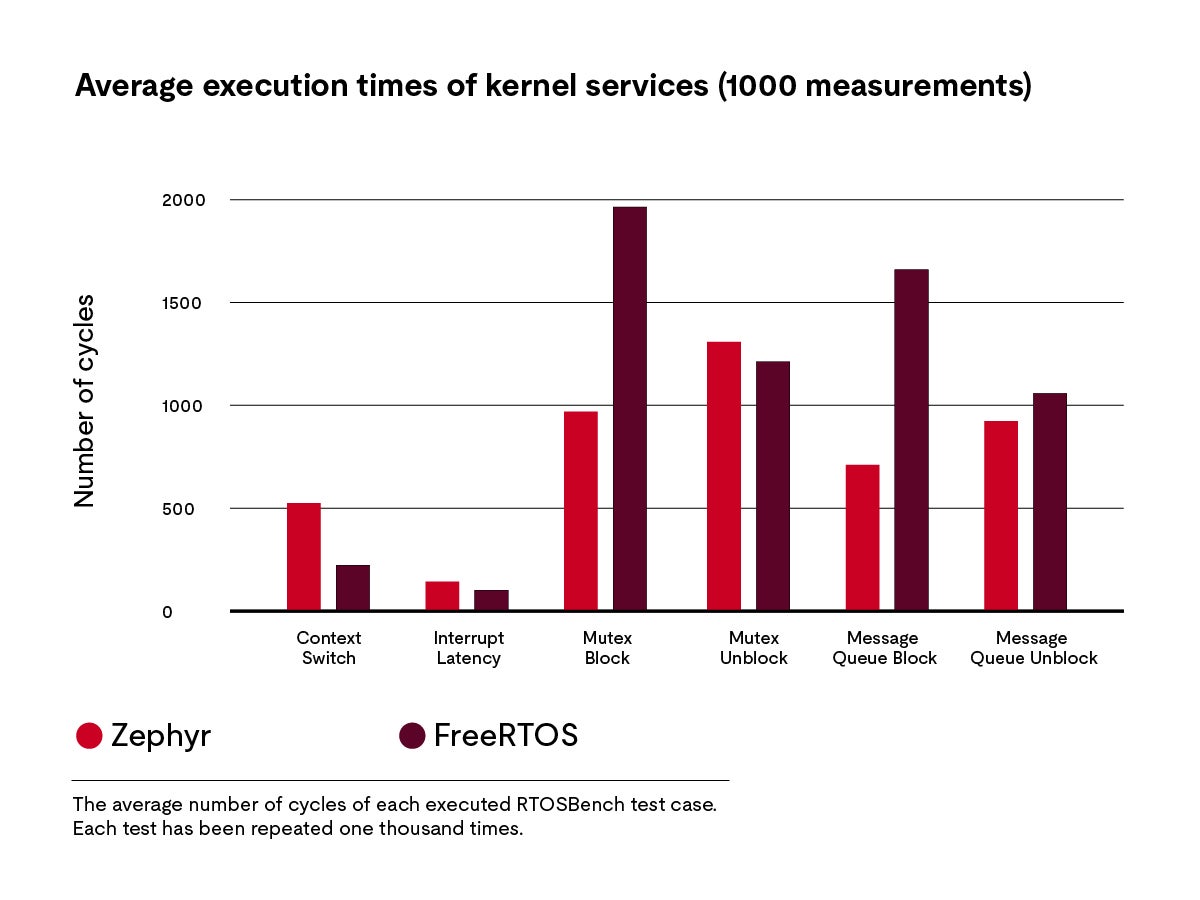
For simplicity’s sake, we only ran a subset of RTOSBench’s tests. The bar chart below shows the average number of cycles for each test.
The average number of cycles of each executed RTOSBench test case. Each test has been repeated one thousand times.
Context Switches
The first test (“Context Switch“) measures the time from one cooperative task voluntarily yielding the CPU to the execution of the next task. Here, Zephyr requires more than twice as many cycles (524) as FreeRTOS (223). This is a significant difference between both operating systems. Therefore, it is important to verify the execution time measured for Zephyr.
Fortunately, Zephyr’s own test suite provides a benchmark (located at tests/benchmarks/latency_measure in Zephyr’s source tree) which also covers cooperative context switches.
We can verify our result by comparing it to that from Zephyr’s test suite. Executing Zephyr’s benchmark yielded an average cooperative context switch latency of 468 cycles. The difference of 56 cycles might be attributed to the overhead produced by RTOSBench. As the results are relatively close to each other, it is a good indication that our original result should be valid.
Interrupt Latency
The second benchmark (“Interrupt Latency“) measures the time it takes from triggering an interrupt on the board’s interrupt controller, until its respective interrupt service routine is executed. Again, FreeRTOS performs better on average with only 101 cycles compared to Zephyr’s 143 cycles.
Inter-Task Synchronization
The next test scenario consists of two parts and tests the performance of a well-known synchronization mechanism: mutexes. Here the bars named “Mutex Block“ show the latency of blocking a task if another task already holds the mutex. This process takes Zephyr only 969 cycles, while FreeRTOS requires 1964.
A possible explanation for the significant difference in execution time might be that FreeRTOS reuses its code for message queues to implement mutexes, while Zephyr uses a separate mutex implementation. This allows Zephyr to optimize it implementation at the cost of a larger code base. “Mutex Unblock“ shows the time it takes from releasing a mutex until a task waiting for the same mutex is executed. This operation is slightly faster on FreeRTOS, taking 1212 cycles on average compared to 1309 cycles on Zephyr.
Inter-Task Communication
Finally, the results for the message queue benchmarks look similar to those of the mutex test case. The bars termed “Message Queue Block“ show the average number of cycles it takes for a task to block on an empty message queue, including the time of a context switch to the next task. This operation takes Zephyr 710 cycles, while FreeRTOS requires 1660 cycles. “Message Queue Unblock“ provides the latency between sending a message to the message queue and waking up a (higher priority) task that waits for a message on the same queue. With 923 cycles Zephyr performs this task slightly faster than FreeRTOS which requires 1058 cycles.
Conclusion
We used Zephyr and FreeRTOS as example operating systems for this exercise. However, the results presented here should not be taken as proof that one operating system is better than the other. However, these results might serve as an indication that one operating system is better suited for a specific use case. For example, FreeRTOS might work better for context-switch-heavy applications, while Zephyr could be a better fit for applications with a lot of inter-task communication.
Another thing to keep in mind is that both operating systems offer many configuration parameters that might affect benchmark results when tuned for your specific application. In general, you should tune the respective kernel to your application’s needs before performing these benchmarks.
When taking a closer look at the results, it seems suspicious that blocking operations on FreeRTOS take significantly longer than on Zephyr. A possible next step for further investigation would be to use FreeRTOS’s tracing capabilities for a closer look at what is happening.
X
Get connected with our team
Thanks for your interest in our products and services. Let's collect some information so we can connect you with the right person.
Please wait…
Characters remaining